Advanced Disk Modeling
This tutorial builds on the fundamental disk modeling tutorial to show a parameter estimation for real data using MCMC—we use the affine-invariant ensemble sampler implementation of MCMC from `emcee <https://emcee.readthedocs.io/en/stable/>`__ (Foreman-Mackey+ 2012).
The data used in this tutorial is HD 115600 in H-band polarimetry from the Gemini Planet Imager debris disk survey (Esposito+ 2020), and is publicly available on the CANFAR archive (Crotts+ 2025).
Note: This notebook was run on an NVIDIA GeForce RTX 4090
[ ]:
from astropy.io import fits
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ['XLA_PYTHON_CLIENT_MEM_FRACTION'] = '0.15'
jax.config.update("jax_enable_x64", True)
Loading and Processing Files
For this tutorial using real data, we begin with starting parameter guesses from published literature values where possible.
[2]:
# GPI Image Initial Parameter Reference
# Name Radius Inclination Position Angle Distance Knots
# hd115600_H_pol 46.0 80.0 27.5 109.62 6
row = {'Name': 'hd115600_H_pol', 'Radius': 51.0, 'Inclination': 85.0, "Position Angle": 27.5, "Distance": 109.62, "Knots": 6}
[3]:
from grater_jax.optimization.optimize_framework import OptimizeUtils
fits_image_filepath = "tutorial_images/" + row['Name'] + ".fits"
hdul = fits.open(fits_image_filepath)
#Displays File Info
hdul.info()
# Gets Image
target_image = OptimizeUtils.process_image(hdul['SCI'].data[1,:,:], bounds=(70, 210, 70, 210))
# Displays Image
plt.imshow(target_image, origin='lower', cmap='inferno')
plt.title("HD 115600 Image from Fits File")
Filename: tutorial_images/hd115600_H_pol.fits
No. Name Ver Type Cards Dimensions Format
0 PRIMARY 1 PrimaryHDU 523 ()
1 SCI 1 ImageHDU 142 (281, 281, 4) float32
2 DQ 3 ImageHDU 64 (281, 281, 2) uint8
[3]:
Text(0.5, 1.0, 'HD 115600 Image from Fits File')

Getting Optimal Disk Fit
[4]:
from grater_jax.optimization.optimize_framework import Optimizer, OptimizeUtils
from grater_jax.disk_model.objective_functions import objective_model, objective_ll, objective_fit, Parameter_Index
from grater_jax.disk_model.SLD_ojax import ScatteredLightDisk
from grater_jax.disk_model.SLD_utils import *
Initializing Relevant Parameters
The disk fit begins with processing the target image and creating an error map, setting up the empirical PSF (if desired), and then initializing a disk model in the optimizer class with some starting parameters.
The error map is generated from the \(U_\phi\) image of the GPI polarimetric data, as that should be an estimate of the noise and should not contain disk signal.
[5]:
target_image = OptimizeUtils.process_image(hdul['SCI'].data[1,:,:], bounds=(70, 210, 70, 210))
err_map = OptimizeUtils.process_image(OptimizeUtils.create_empirical_err_map(hdul['SCI'].data[2,:,:]), bounds=(70, 210, 70, 210)) #, outlier_pixels=[(57, 68)]))
/home/mihirkondapalli/anaconda3/envs/package-env/lib/python3.12/site-packages/numpy/lib/_nanfunctions_impl.py:2019: RuntimeWarning: Degrees of freedom <= 0 for slice.
var = nanvar(a, axis=axis, dtype=dtype, out=out, ddof=ddof,
[6]:
scale_factor = 1
image = fits.open("tutorial_images/GPI_Hband_PSF.fits")[0].data[0,:,:]
scaled_image = (image[::scale_factor, ::scale_factor])[1::, 1::]
cropped_image = image[70:211, 70:211]
def safe_float32_conversion(value):
try:
return np.float32(value)
except (ValueError, TypeError):
print("This value is unjaxable: " + str(value))
emp_psf_image = np.nan_to_num(cropped_image)
emp_psf_image = np.vectorize(safe_float32_conversion)(emp_psf_image)
There are three setup steps before optimization:
``opt.inc_bound_knots()`` — Uses the starting inclination guess to set
forwardscatt_boundandbackscatt_bound, restricting knots to the scattering angles actually probed at this inclination. A face-on disk probes a narrow angular range and needs fewer knots than an edge-on one. Only use this if you have a reasonable inclination estimate. Values outside the knot range are extrapolated: linear on the forward scattering side (to capture physically motivated forward-scattering behavior), and constant at the backscattering boundary.``opt.set_empirical_psf(emp_psf_image)`` — Loads the empirical PSF image into the
EMP_PSFclass. Only needed when using an empirical PSF.``opt.warm_start_knots(init_g=0.5)`` — The spline SPF is normalized to 1 at 90 degrees (cos_phi = 0) by construction, so
flux_scalingcarries the absolute brightness. This method initialises knot values from a normalized Henyey-Greenstein shape evaluated at each free knot position, avoiding the flat-spline local minimum that an all-ones initialization produces at low inclinations.init_gis an assumed asymmetry parameter — not a constraint on the fit.``opt.estimate_flux_scaling(target_image)`` — Estimates a starting
flux_scalingby matching the model peak to the 99th-percentile brightness of unmasked pixels in the target image. Bothknot_valuesandflux_scalingare then fit jointly by the optimizer. This is just one way of getting an estimated flux scaling to start, and the user is ultimately responsible for finding a starting flux scaling that works for their data.
If you have a coronagraph with substantial throughput loss beyond the mask position, it may be preferable to include this throughput correction in the modeling. If this is the case, you can create your own map of throughput and pass it to opt.set_throughput()
[7]:
start_disk_params = Parameter_Index.disk_params.copy()
start_spf_params = InterpolatedUnivariateSpline_SPF.params.copy()
start_psf_params = EMP_PSF.params.copy()
start_misc_params = Parameter_Index.misc_params.copy()
start_disk_params["sma"] = row["Radius"]
start_disk_params["inclination"] = row["Inclination"]
start_disk_params["position_angle"] = row["Position Angle"]
start_spf_params["num_knots"] = int(row["Knots"])
start_misc_params["distance"] = row["Distance"]
start_disk_params["x_center"] = target_image.shape[1] / 2
start_disk_params["y_center"] = target_image.shape[0] / 2
opt = Optimizer(ScatteredLightDisk, DustEllipticalDistribution2PowerLaws, InterpolatedUnivariateSpline_SPF, EMP_PSF,
start_disk_params, start_spf_params, start_psf_params, start_misc_params)
# Set knot angle bounds from the assumed inclination.
opt.inc_bound_knots()
opt.set_empirical_psf(emp_psf_image)
# Apply the GPI coronagraph throughput map. This accounts for the position-dependent
# attenuation of the coronagraph across the field of view.
from astropy.io import fits as astrofits
throughput = astrofits.open("tutorial_images/GPI_H_throughput_map.fits")[0].data
opt.set_throughput(throughput)
# Warm-start knot values from a normalised HG shape evaluated at the free knot positions.
# init_g is the assumed asymmetry parameter — not a constraint on the fit.
opt.warm_start_knots(init_g=0.5)
# Estimate a starting flux_scaling by matching the model peak to the target image.
flux_scaling = opt.estimate_flux_scaling(target_image)
print(f"Estimated flux_scaling: {flux_scaling:.3g}")
Estimated flux_scaling: 255
JIT Compiling and Disk Modeling
If you would like to use the autodiff functionality in your models, you need to explicitly compile the gradient for the JIT compilation using opt.jit_compile_gradient as shown below.
Note: Autodiff is Jitted by default to enable faster runtime.
[8]:
opt.jit_compile_model() # <-- opt.log_likelihood is also jit compiled by this
opt.jit_compile_gradient(target_image, err_map) # <-- Not needed if gradient isn't going to be used
[9]:
print(opt.log_likelihood(target_image, err_map))
opt.get_gradient(['sma', 'alpha_in', 'knot_values'], target_image, err_map)
-43895.499228595254
[9]:
[Array(22.81860136, dtype=float64),
Array(19.18142766, dtype=float64),
Array([ 0.98747152, 58.90176266, 26.96178498, 6.90583115,
-37.10435859, -19.49999701], dtype=float64)]
[10]:
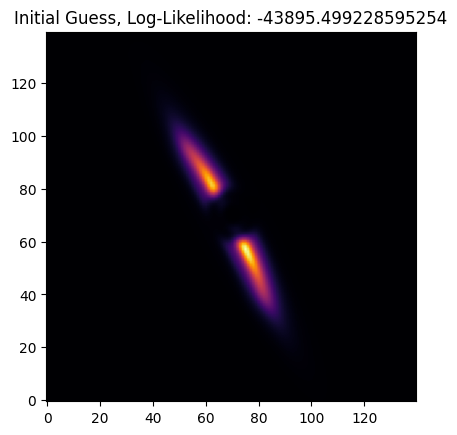
plt.imshow(opt.get_model(), origin='lower', cmap='inferno')
plt.title(f"Initial Guess, Log-Likelihood: {opt.log_likelihood(target_image, err_map)}")
[10]:
Text(0.5, 1.0, 'Initial Guess, Log-Likelihood: -43895.499228595254')
[11]:
opt.print_params()
Disk Params: {'accuracy': 0.005, 'alpha_in': 5, 'alpha_out': -5, 'sma': 51.0, 'e': 0.0, 'ksi0': 3.0, 'gamma': 2.0, 'beta': 1.0, 'rmin': 0.0, 'dens_at_r0': 1.0, 'inclination': 85.0, 'position_angle': 27.5, 'x_center': 70.0, 'y_center': 70.0, 'omega': 0.0}
SPF Params: {'backscatt_bound': Array(-0.9961947, dtype=float64, weak_type=True), 'forwardscatt_bound': Array(0.9961947, dtype=float64, weak_type=True), 'num_knots': 6, 'knot_values': Array([10.92984453, 3.11646968, 1.58908473, 0.70230955, 0.52772533,
0.41513937], dtype=float64)}
PSF Params: {'scale_factor': 1.0, 'offset': 1.0}
Stellar PSF Params: None
Misc Params: {'distance': 109.62, 'pxInArcsec': 0.01414, 'nx': 140, 'ny': 140, 'halfNbSlices': 25, 'flux_scaling': 255.12242126464844}
JAX can be particularly troublesome with NaNs and infinities, as it does not handle them as Numpy does—the below functions can be enabled to help debug JAX errors that may arise.
[12]:
# Can enable these to debug jax issues
# jax.config.update('jax_debug_nans', True)
# jax.config.update('jax_debug_infs', True)
Running Optimization
With the Optimizer class, parameters to fit are specified with fit_keys. Any key from disk_params, spf_params, psf_params, or misc_params can be included. Log-scaling a parameter (via logscaled_params) helps when it may span orders of magnitude — the optimizer works in log space and the result is automatically exponentiated back. Array-valued parameters like knot_values must be listed in array_params as well.
Since the spline SPF is normalized to 1 at 90 degrees, flux_scaling is the true absolute brightness of the model. We include it in fit_keys and log-scale it so the optimizer finds the correct brightness alongside the disk geometry and SPF shape. Running scipy first (before MCMC) gives a good starting point that reduces burn-in time.
It is also sometimes helpful to run the scipy optimization twice to reset the optimizer if you have a particularly tricky disk. This is demonstrated below.
[13]:
fit_keys = ['alpha_in', 'alpha_out', 'sma', 'inclination', 'position_angle', 'x_center', 'y_center', 'knot_values', 'e', 'flux_scaling']
# Log-scale knot_values (can span orders of magnitude) and flux_scaling (same reason).
logscaled_params = ['knot_values', 'flux_scaling']
array_params = ['knot_values']
nk = opt.spf_params["num_knots"]
bounds = (
[0.1, -15, 0, 0, 0, 60, 60, np.ones(nk)*1e-4, 0, 1e-2],
[20, -0.1, 150, 180, 400, 80, 80, 1e4*np.ones(nk), 1, 1e8 ],
)
opt.scipy_bounded_optimize(fit_keys, bounds, logscaled_params, array_params, target_image, err_map,
use_grad=True, disp_soln=True, iters=2000)
# Second scipy pass: reset Hessian and continue from current solution.
opt.scipy_bounded_optimize(fit_keys, bounds, logscaled_params, array_params, target_image, err_map,
use_grad=True, disp_soln=True, iters=2000, maxls=50)
optimal_image = opt.get_model()
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 15 M = 10
At X0 1 variables are exactly at the bounds
At iterate 0 f= 2.23957D+00 |proj g|= 1.56992D-02
At iterate 1 f= 2.23890D+00 |proj g|= 1.50904D-02
Bad direction in the line search;
refresh the lbfgs memory and restart the iteration.
At iterate 2 f= 2.23583D+00 |proj g|= 1.44513D-02
At iterate 3 f= 2.22908D+00 |proj g|= 1.85747D-02
At iterate 4 f= 2.22328D+00 |proj g|= 6.20997D-02
At iterate 5 f= 2.20842D+00 |proj g|= 3.88126D-02
At iterate 6 f= 2.17724D+00 |proj g|= 1.31800D-02
At iterate 7 f= 2.17629D+00 |proj g|= 1.37469D-02
At iterate 8 f= 2.17574D+00 |proj g|= 1.13038D-02
At iterate 9 f= 2.17532D+00 |proj g|= 8.91863D-03
At iterate 10 f= 2.17457D+00 |proj g|= 9.10146D-03
At iterate 11 f= 2.17156D+00 |proj g|= 3.81201D-02
At iterate 12 f= 2.16973D+00 |proj g|= 4.18316D-02
At iterate 13 f= 2.16689D+00 |proj g|= 1.76053D-02
At iterate 14 f= 2.16558D+00 |proj g|= 1.60432D-02
At iterate 15 f= 2.16494D+00 |proj g|= 1.54027D-02
At iterate 16 f= 2.16432D+00 |proj g|= 1.11742D-02
At iterate 17 f= 2.16295D+00 |proj g|= 4.74053D-03
At iterate 18 f= 2.16195D+00 |proj g|= 7.43863D-03
At iterate 19 f= 2.16154D+00 |proj g|= 1.79773D-03
At iterate 20 f= 2.16144D+00 |proj g|= 1.13397D-03
At iterate 21 f= 2.16128D+00 |proj g|= 1.78781D-03
At iterate 22 f= 2.16097D+00 |proj g|= 1.40641D-03
At iterate 23 f= 2.16045D+00 |proj g|= 4.14987D-03
At iterate 24 f= 2.15979D+00 |proj g|= 4.92360D-03
At iterate 25 f= 2.15965D+00 |proj g|= 4.70303D-03
At iterate 26 f= 2.15954D+00 |proj g|= 3.46274D-04
At iterate 27 f= 2.15954D+00 |proj g|= 3.40969D-04
At iterate 28 f= 2.15954D+00 |proj g|= 3.37348D-04
At iterate 29 f= 2.15951D+00 |proj g|= 4.36156D-04
At iterate 30 f= 2.15947D+00 |proj g|= 1.11969D-03
At iterate 31 f= 2.15946D+00 |proj g|= 1.09932D-03
At iterate 32 f= 2.15946D+00 |proj g|= 1.09527D-03
message: CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
success: True
status: 0
fun: 2.159460954887175
x: [ 4.772e+00 -7.879e+00 ... 0.000e+00 6.283e+00]
nit: 33
jac: [ 2.579e-04 -2.499e-04 ... 6.104e-03 -1.095e-03]
nfev: 100
njev: 100
hess_inv: <15x15 LbfgsInvHessProduct with dtype=float64>
At iterate 33 f= 2.15946D+00 |proj g|= 1.09527D-03
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
15 33 108 36 0 1 1.095D-03 2.159D+00
F = 2.1594609548871748
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 15 M = 10
At X0 1 variables are exactly at the bounds
At iterate 0 f= 2.15946D+00 |proj g|= 1.09527D-03
message: CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
success: True
status: 0
fun: 2.159460954887175
x: [ 4.772e+00 -7.879e+00 ... 0.000e+00 6.283e+00]
nit: 1
jac: [ 2.579e-04 -2.499e-04 ... 6.104e-03 -1.095e-03]
nfev: 5
njev: 5
hess_inv: <15x15 LbfgsInvHessProduct with dtype=float64>
At iterate 1 f= 2.15946D+00 |proj g|= 1.09527D-03
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
15 1 5 1 0 1 1.095D-03 2.159D+00
F = 2.1594609548871748
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
Warning: more than 10 function and gradient
evaluations in the last line search. Termination
may possibly be caused by a bad search direction.
Results
[14]:
fig, axes = plt.subplots(1,3, figsize=(20,10))
mask = OptimizeUtils.get_mask(target_image)
vmin = np.nanpercentile(target_image[mask], 10)
vmax = np.nanpercentile(target_image[mask], 90)
im = axes[0].imshow(target_image, origin='lower', cmap='inferno')
axes[0].set_title("Original Image")
plt.colorbar(im, ax=axes[0], shrink=0.75)
im.set_clim(vmin, vmax)
im = axes[1].imshow(optimal_image, origin='lower', cmap='inferno')
axes[1].set_title("Disk Fit")
plt.colorbar(im, ax=axes[1], shrink=0.75)
im.set_clim(vmin, vmax)
im = axes[2].imshow(target_image-optimal_image, origin='lower', cmap='inferno')
axes[2].set_title("Residual")
plt.colorbar(im, ax=axes[2], shrink=0.75)
im.set_clim(vmin, vmax)
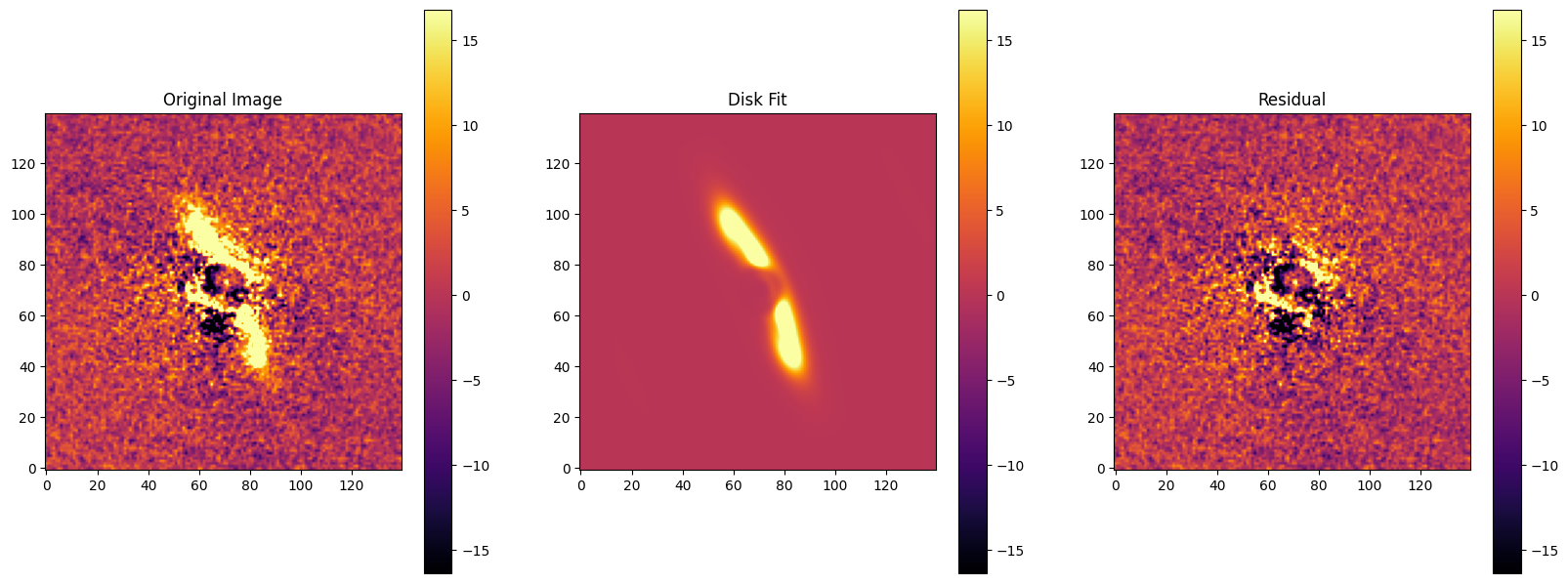
Since the spline SPF is internally normalized to 1 at 90 degrees (cos_phi = 0), flux_scaling is already the true physical flux normalization and no additional rescaling is needed after the fit. The parameters below reflect the best-fit values found by scipy.
[15]:
opt.print_params()
Disk Params: {'accuracy': 0.005, 'alpha_in': np.float64(4.77206771891701), 'alpha_out': np.float64(-7.879340791298166), 'sma': np.float64(49.79863403007286), 'e': np.float64(0.0), 'ksi0': 3.0, 'gamma': 2.0, 'beta': 1.0, 'rmin': 0.0, 'dens_at_r0': 1.0, 'inclination': np.float64(81.43196710992206), 'position_angle': np.float64(24.61419511514676), 'x_center': np.float64(73.19418885955844), 'y_center': np.float64(73.5710444031452), 'omega': 0.0}
SPF Params: {'backscatt_bound': Array(-0.9961947, dtype=float64, weak_type=True), 'forwardscatt_bound': Array(0.9961947, dtype=float64, weak_type=True), 'num_knots': 6, 'knot_values': array([12.59981751, 3.43326278, 3.24851395, 2.38565323, 1.0265323 ,
0.25135777])}
PSF Params: {'scale_factor': 1.0, 'offset': 1.0}
Stellar PSF Params: None
Misc Params: {'distance': 109.62, 'pxInArcsec': 0.01414, 'nx': 140, 'ny': 140, 'halfNbSlices': 25, 'flux_scaling': np.float64(535.5359739953063)}
For MCMC, we recommend log-scaling knot_values and flux_scaling — log-space sampling keeps the chains well-conditioned when values can span orders of magnitude. The Optimizer passes them in as logarithms and exponentiates them internally.
The chain is saved during the run via emcee’s HDF5 backend. If a backend file already exists a confirmation prompt will appear unless confirm_overwrite=False is set (useful in scripted or non-interactive contexts). The default backend filename is test_emcee_backend.h5; change opt.name to use a different prefix.
The chain used here is far too short for reliable parameter estimation and is provided only to show the workflow. Consult the emcee documentation on autocorrelation-based convergence diagnostics to determine appropriate chain lengths for your science case.
Note that MCMC is not compatible with automatic differentiation! However, it still benefits from the speed ups from GPUs and JIT.
[16]:
fit_keys = ['alpha_in', 'alpha_out', 'sma', 'inclination', 'position_angle', 'x_center', 'y_center', 'knot_values', 'e', 'flux_scaling']
logscaled_params = ['knot_values', 'flux_scaling']
array_params = ['knot_values']
nk = opt.spf_params["num_knots"]
bounds = (
[0.1, -15, 0, 0, 0, 60, 60, np.ones(nk)*1e-4, 0, 1e-2],
[200, -0.1, 150, 180, 400, 80, 80, 1e4*np.ones(nk), 1, 1e8 ],
)
mc_model = opt.mcmc(fit_keys, logscaled_params, array_params, target_image, err_map, bounds,
nwalkers=100, niter=100, burns=20, confirm_overwrite=False)
Running burn-in...
0%| | 0/20 [00:00<?, ?it/s]/home/mihirkondapalli/anaconda3/envs/package-env/lib/python3.12/site-packages/emcee/moves/red_blue.py:99: RuntimeWarning: invalid value encountered in scalar subtract
lnpdiff = f + nlp - state.log_prob[j]
100%|██████████| 20/20 [00:05<00:00, 3.60it/s]
Running production...
100%|██████████| 100/100 [00:28<00:00, 3.47it/s]
The function model_obj.get_theta_median will return the median parameters as estimated by the MCMC. Setting scaled = True will return the scaled spline SPF values (i.e. un-log-scaled).
[17]:
mc_soln = mc_model.get_theta_median(scaled = True)
img = opt.get_model()
[18]:
fig, axes = plt.subplots(1,3, figsize=(20,10))
mask = OptimizeUtils.get_mask(target_image)
vmin = np.nanpercentile(target_image[mask], 10)
vmax = np.nanpercentile(target_image[mask], 90)
im = axes[0].imshow(target_image, origin='lower', cmap='inferno')
axes[0].set_title("Original Image")
plt.colorbar(im, ax=axes[0], shrink=0.75)
im.set_clim(vmin, vmax)
im = axes[1].imshow(img, origin='lower', cmap='inferno')
axes[1].set_title("MCMC Fit")
plt.colorbar(im, ax=axes[1], shrink=0.75)
im.set_clim(vmin, vmax)
im = axes[2].imshow(target_image-img, origin='lower', cmap='inferno')
axes[2].set_title("Residual")
plt.colorbar(im, ax=axes[2], shrink=0.75)
im.set_clim(vmin, vmax)
plt.title("Post MCMC Residuals")
[18]:
Text(0.5, 1.0, 'Post MCMC Residuals')
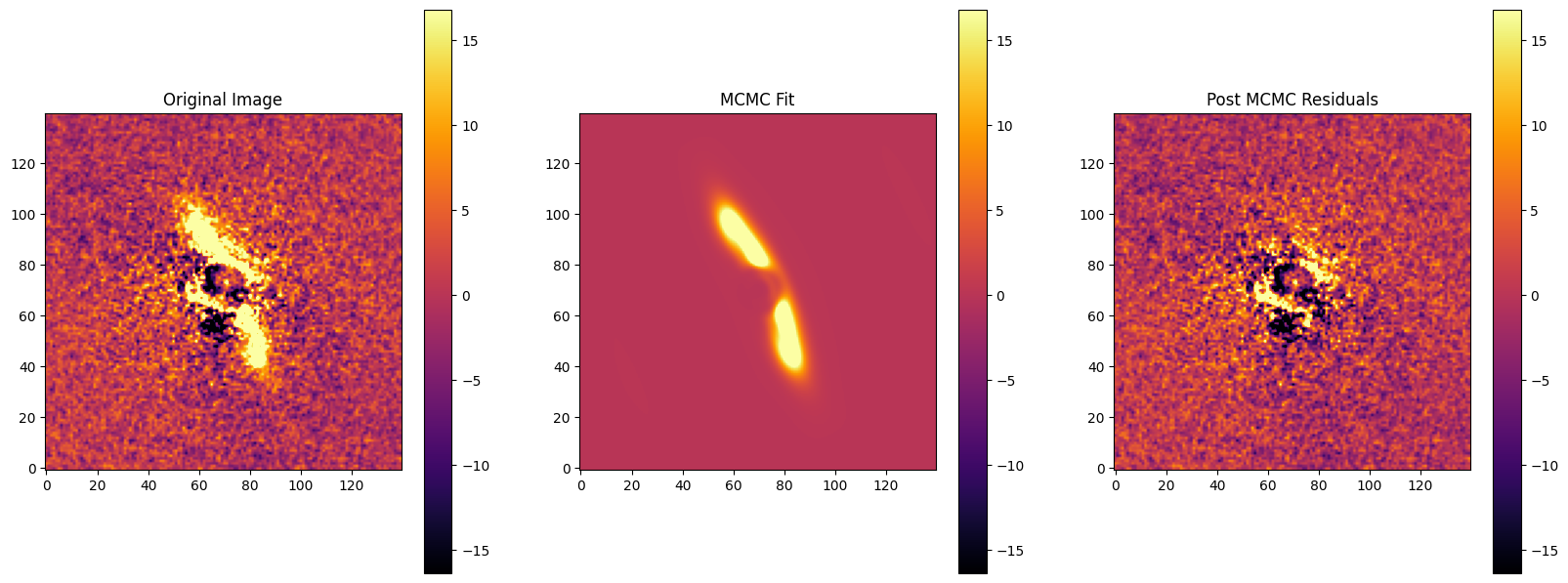
Plotting MCMC Results
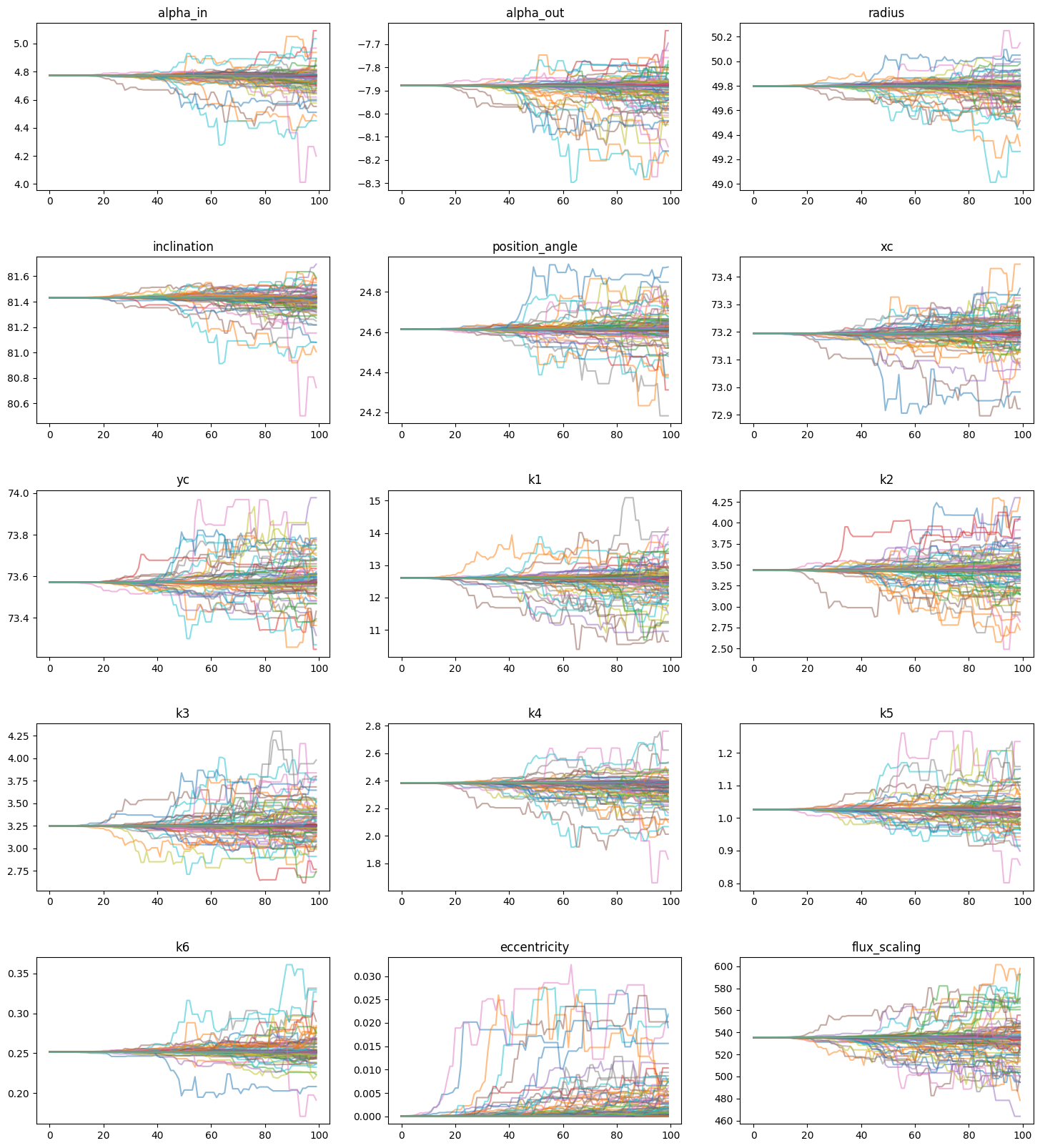
Various MCMC diagnostics are incorporated into the optimizer class, such as viewing the MCMC chains and creating a corner plot with `corner.py <https://corner.readthedocs.io/en/latest/>`__. Again, you can use the boolean keyword scaled to scale the spline SPF chains and resulting parameters automatically. Labels for the chains must be entered, and are almost equivalent to the fit_keys list, except for any array-like parameters (e.g. the knot values).
[19]:
# Labels must match the order of fit_keys, with array parameters (knot_values)
# expanded into individual entries. fit_keys = ['alpha_in', 'alpha_out', 'sma',
# 'inclination', 'position_angle', 'x_center', 'y_center', 'knot_values', 'e', 'flux_scaling']
labels = ['alpha_in', 'alpha_out', 'radius', 'inclination', 'position_angle', 'xc', 'yc']
for i in range(0, opt.spf_params['num_knots']):
labels.append('k'+str(i+1))
labels.append('eccentricity')
labels.append('flux_scaling')
mc_model.plot_chains(labels, scaled=True)
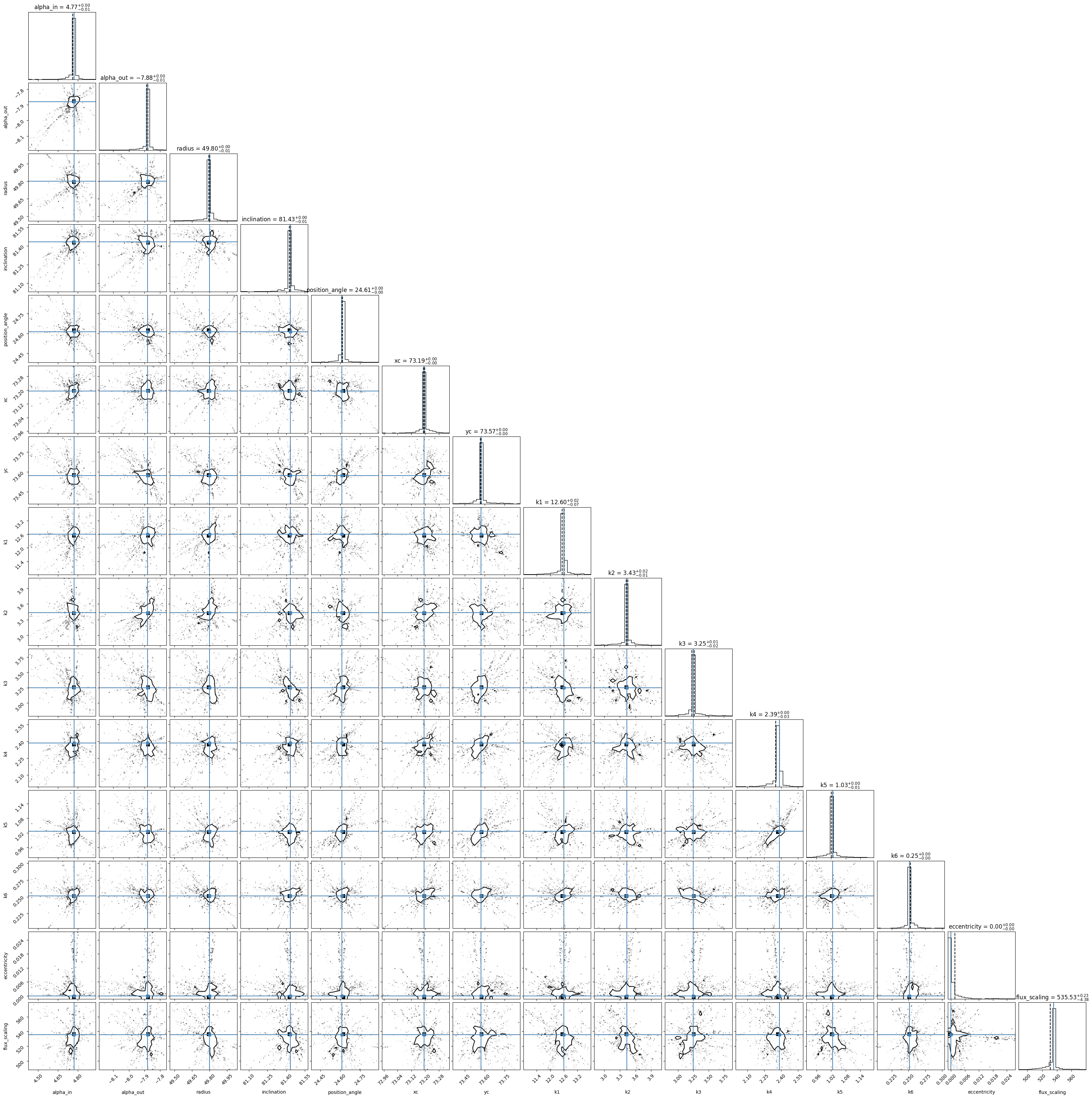
Corner Plot
[20]:
fig = mc_model.show_corner_plot(labels, truths=mc_soln, scaled = True, quiet = True)
[21]:
print(dict(zip(labels, mc_model.get_theta_median(scaled=True))))
{'alpha_in': np.float64(4.772066184961566), 'alpha_out': np.float64(-7.879343971030101), 'radius': np.float64(49.79863430586484), 'inclination': np.float64(81.43196591003023), 'position_angle': np.float64(24.614195112689202), 'xc': np.float64(73.19418746810621), 'yc': np.float64(73.57104520065442), 'k1': np.float64(12.599795590974397), 'k2': np.float64(3.4332620083120635), 'k3': np.float64(3.2485087464647964), 'k4': np.float64(2.385634728780534), 'k5': np.float64(1.0265315928012606), 'k6': np.float64(0.2513586441658591), 'eccentricity': np.float64(1.2265581485664939e-05), 'flux_scaling': np.float64(535.5329623630973)}